QO
About Qwen3 Omni
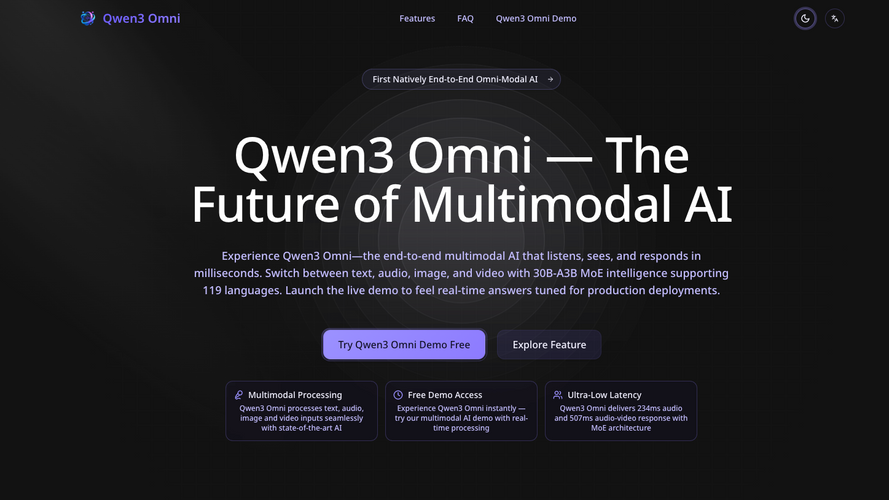
Qwen3 Omni represents a revolutionary advancement in multimodal AI technology, being the first natively end-to-end omni-modal AI model. Built with a sophisticated 30B-A3B Mixture-of-Experts (MoE) architecture, it seamlessly processes text, audio, image, and video inputs simultaneously with unprecedented speed and accuracy.
## Key Features
- **Ultra-Low Latency**: Achieves 234ms audio response and 507ms audio-video latency for real-time interactions
- **Multimodal Processing**: Handles text, audio, image, and video inputs seamlessly in a single model
- **119 Language Support**: Comprehensive language coverage with 19 speech languages supported
- **Free Browser Demo**: Instant access through web browser without any installation required
- **Production Ready**: Optimized for both research and commercial deployment
## Performance Highlights
- State-of-the-art results on 22 out of 36 multimodal benchmarks
- Advanced TMRoPE position embedding for synchronized multimodal understanding
- Open-source accessibility through Apache 2.0 license
- Available on Hugging Face as Qwen/Qwen3-Omni-30B-A3B-Instruct
## Use Cases
Perfect for developers, researchers, and businesses seeking to integrate advanced multimodal AI capabilities into their workflows. Whether for rapid prototyping, production applications, or research projects, Qwen3 Omni provides professional-grade multimodal processing with exceptional performance and accessibility.
Similar Hacks
—
No reviews yet
5
0
4
0
3
0
2
0
1
0
No reviews yet — be the first!
Discussion
Join the conversation
Sign in or create a free account to leave a comment.
Analytics
Unique visitor trends for Qwen3 Omni
43
Total Views
—
This month
—
Avg Rating
0
Discussions
Loading…
No comments yet. Be the first to share your thoughts!