

About xbrain
X Brain – Semantic search for your X/Twitter liked tweets.
I liked thousands of tweets over the years and could never find any of them when I needed them. X's search doesn't work for likes. So I built X Brain.
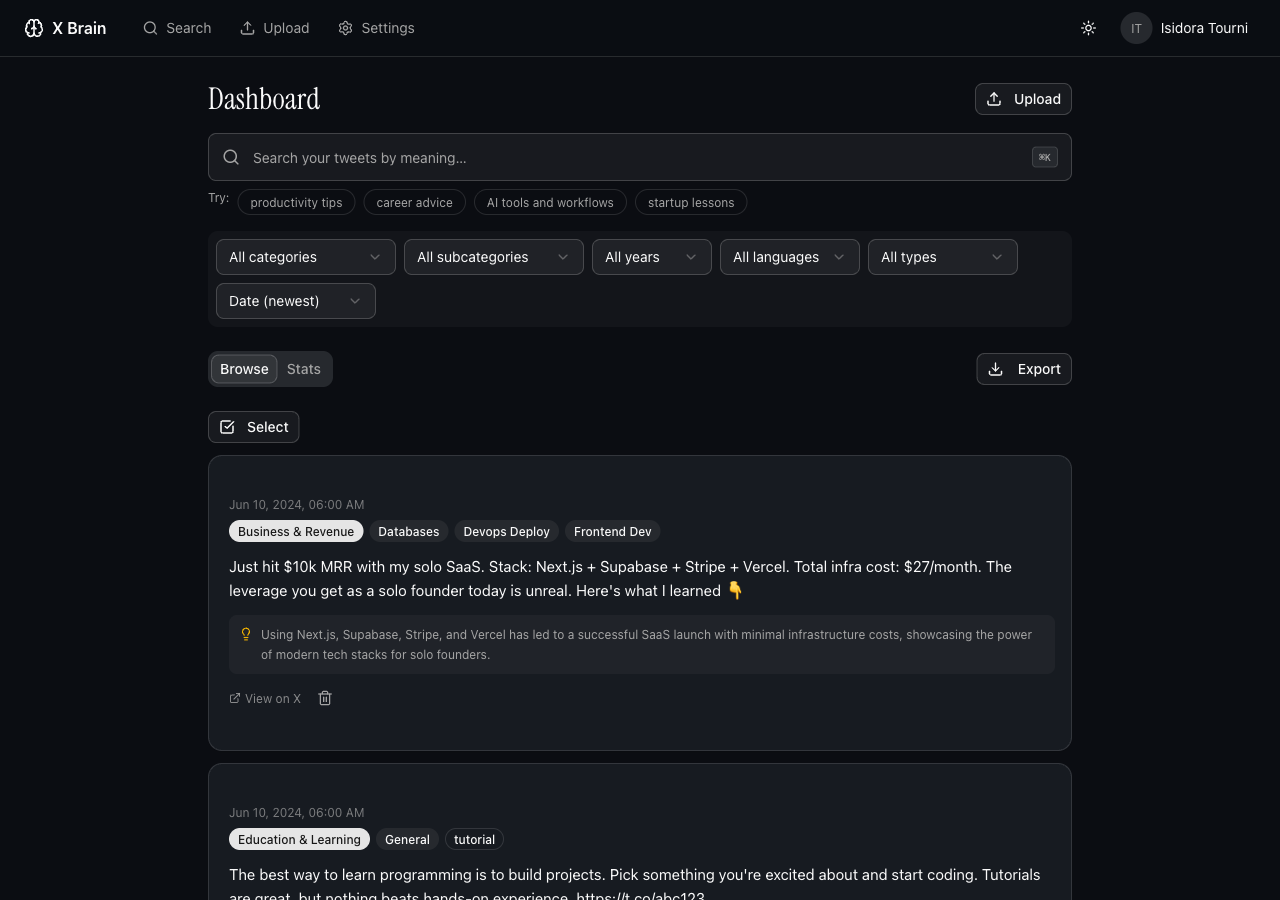
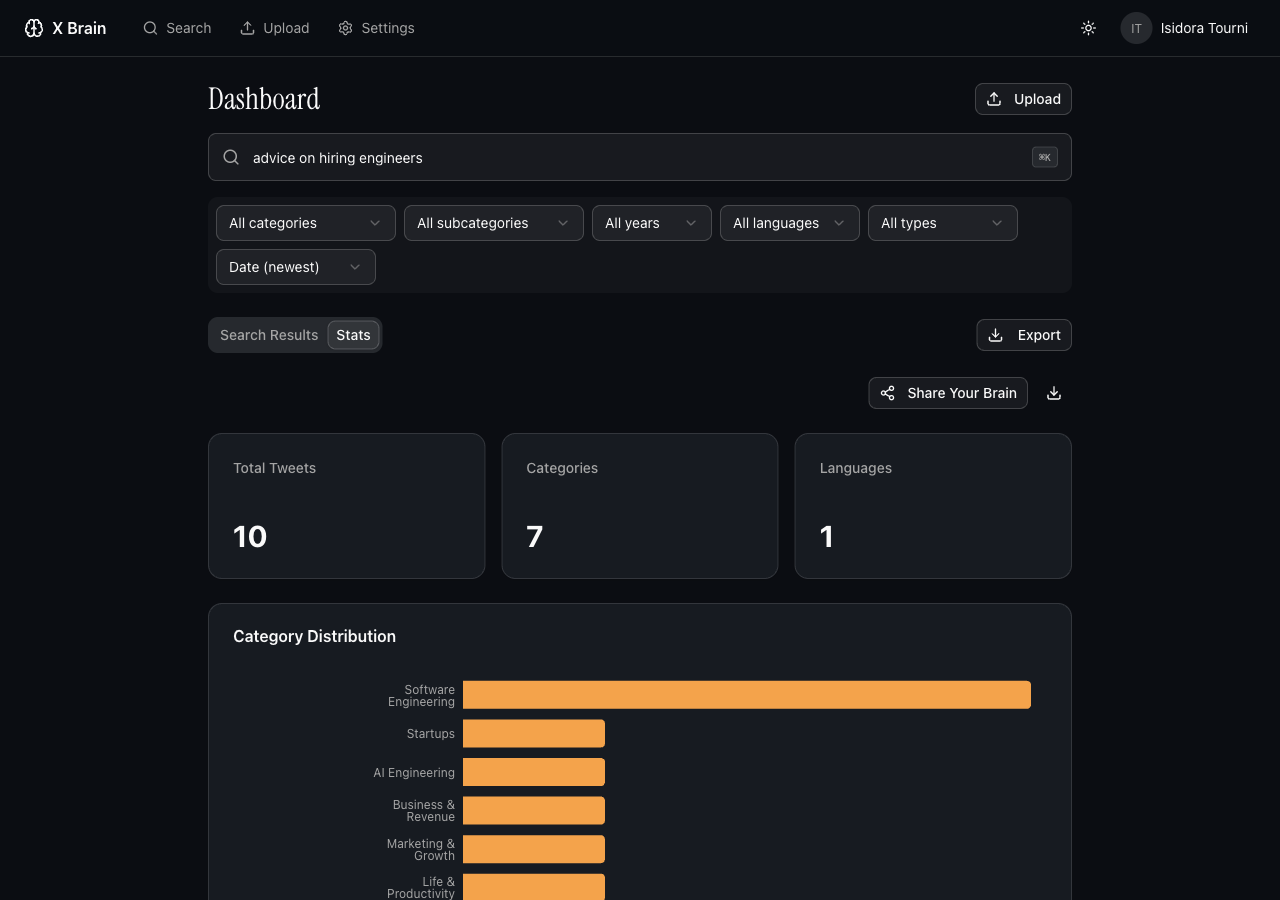
You download your X data archive (the ZIP from Settings), upload it, and the app runs a pipeline: parse the tweet.js file, embed each liked tweet with OpenAI or Gemini embeddings, classify into 15 domains and 65+ subcategories using a structured LLM prompt, extract key takeaways, and store vectors in Supabase pgvector for cosine similarity search.
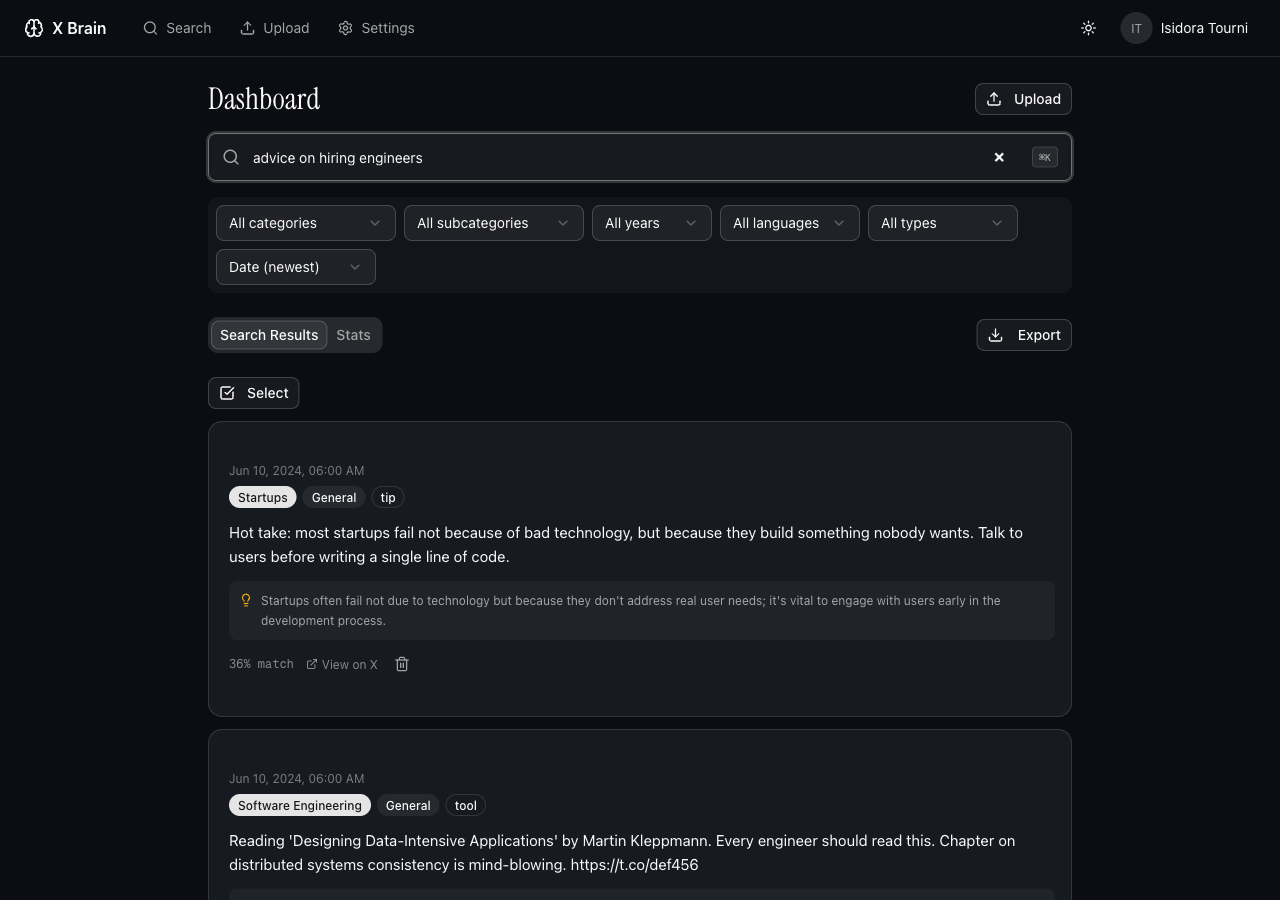
Search is semantic - "advice on dealing with a difficult manager" returns relevant tweets even when none of them use those words.
A few technical things HN might find interesting:
- The pipeline is resumable. If a batch fails mid-way (e.g. at tweet 4,000 of 8,000), it retries from the failed stage without reprocessing what already ran. Each stage writes progress to the DB; the next request picks up from there.
- It's BYOK - you bring your own OpenAI, Anthropic, or Gemini key. Processing a full archive costs $1–3 in API credits. After that, search is free forever. I'm not eating embedding costs.
- The pipeline runs on Vercel serverless functions, chained via Next.js `after()` so the response returns immediately and processing continues in the background without keeping a connection alive.
- Exports an Obsidian-ready vault: one Markdown note per tweet, YAML frontmatter, topic index files, master index.
$19 one-time. No subscription. Data stored in Supabase with row-level security, exportable and deletable anytime.
https://www.xbrain.live
No reviews yet — be the first!
Discussion
Join the conversation
Sign in or create a free account to leave a comment.
Analytics
Unique visitor trends for xbrain
No comments yet. Be the first to share your thoughts!